
OpenAI in the spotlight with New York Times lawsuit and potential Tumblr partnership. (Source – Shutterstock).
OpenAI faces New York Times hacking allegations while exploring deals with Tumblr
- OpenAI battles The New York Times in court and eyes a deal with Tumblr.
- As OpenAI faces The New York Times‘ legal action, Automattic explores AI collaboration.
- The Times is by no means the only organization alleging copyright infringement.
Remember the copyright infringement lawsuit The New York Times filed against OpenAI and Microsoft? The Times has accused the companies of using millions of its articles to train AI technologies, which now rival the newspaper as a source of trustworthy information.
But how can one use OpenAI’s AI technology to their own advantage while simultaneously fighting against OpenAI over how its AI technology is being used?
The New York Times Vs. OpenAI
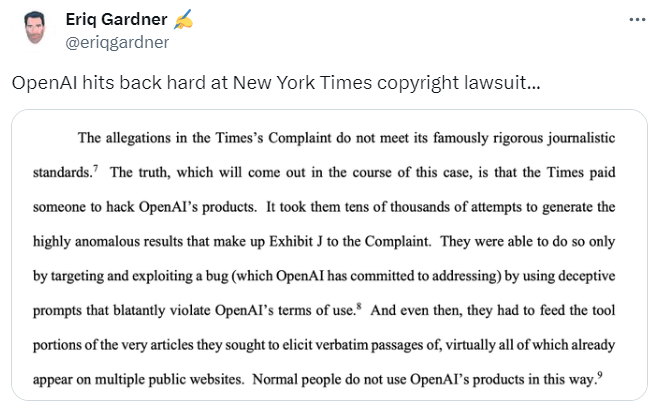
In a significant development, OpenAI, whose AI technology, ChatGPT, is used by The Times to generate content, was reported by Reuters as having requested a federal judge to dismiss parts of the lawsuit. Central to OpenAI’s defense is the allegation that The Times “hacked” its chatbot and other AI systems, producing misleading evidence. This legal move by OpenAI, filed in a Manhattan federal court, claims that The Times manipulated its technology to mirror its content and violated OpenAI’s terms of use through deceptive prompts.


OpenAI further asserts that The Times took advantage of a flaw in the AI system, which is under active remediation, to feed its articles directly into the chatbot. This resulted in the chatbot regurgitating exact passages, a use case that OpenAI emphasizes is atypical, pointing to a Times article from April 2023 about real-world AI applications for context.
OpenAI’s criticism of The Times is sharp, highlighting that the newspaper’s complaint does not meet its own high journalistic standards. OpenAI’s contention is that the case will reveal that The Times paid someone to manipulate OpenAI’s products deliberately.
Got a headache yet?
The Times‘ lead counsel, Ian Crosby, addressed these accusations in a statement to The Verge. He challenged the hacking allegation, clarifying that the newspaper was simply employing OpenAI’s products to gather evidence of potential copyright infringement. Crosby noted that OpenAI has not contested the claim that it copied The Times’ work without authorization.
OpenAI refrained from identifying the individual purportedly engaged by The Times to tamper with its systems, and stopped short of accusing the newspaper of breaking anti-hacking laws.
OpenAI addresses The New York Times copyright lawsuit. (Source – AI).
The New York Times fights back: defending its use of AI
In its legal strategy, OpenAI aims to dismiss some aspects of The Times’ copyright infringement claim, specifically those related to reproductions dating back more than three years before the lawsuit. OpenAI also wants to negate other accusations, including contributory infringement, failure to remove infringing content, and engaging in unfair competition through misappropriation. The lawsuit filed by The Times encompasses broader allegations, extending to trademark dilution, common law unfair competition, and vicarious copyright infringement.
The situation mirrors OpenAI’s previous legal challenge, where it managed to narrow down a lawsuit involving Sarah Silverman and other authors to a singular claim of direct copyright infringement. As legal battles against AI firms escalate, industry observers like Nilay Patel and Sarah Jeong from The Verge’s Decoder podcast discuss the ramifications of such lawsuits on the burgeoning AI industry.
The Times represents just one among a cohort of copyright owners, including authors, visual artists, and music publishers, challenging tech companies for purportedly misappropriating their creative works in AI training.
Tech companies, for their part, defend their AI systems’ use of copyrighted material as fair use, cautioning that these legal challenges might impede the progress of a potentially multitrillion-dollar industry.
As the legal landscape evolves, courts have yet to conclusively decide whether AI training qualifies as fair use under copyright law. Several infringement claims against generative AI systems have been dismissed, primarily due to insufficient proof that AI-generated content closely resembles copyrighted works.
Tumblr’s owner to collaborate with OpenAI?
In a separate but related development, a report from 404 Media has alleged that Automattic, the owner of Tumblr and WordPress.com, is engaging in advanced discussions with AI firms Midjourney and OpenAI. An anonymous source within Automattic hinted at imminent deals to harness user-generated content as training data for AI, following speculative chatter on Tumblr about a potential Midjourney collaboration that might open new revenue streams for the platform.
404 Media‘s report sheds light on Automattic’s forthcoming update, slated for 28th of February, introducing a feature that lets users opt out of data sharing with third parties, including AI entities. This update comes amid revelations from internal communications about a comprehensive data extraction that inadvertently included non-public content, encompassing Tumblr’s public posts from 2014 to 2023. Questions linger about the handling and potential sharing of this extensive dataset with Midjourney and OpenAI.
In response to these claims, Automattic released a statement titled “Protecting User Choice.” Following the 404 Media report, this statement vaguely alludes to partnerships with unnamed AI companies. Automattic affirms its default stance of blocking major AI platform crawlers and its commitment to only sharing public content from WordPress.com and Tumblr with entities that adhere to opt-out preferences. The statement underscores Automattic’s collaboration with AI firms that align with community values, including user attribution, opt-out options, and overarching control.
The recent trend of companies forging agreements with AI technology developers for training data, traditionally sourced from publicly accessible online content, underscores a growing legal complexity. High-profile cases include Reddit’s reported US$60 million annual deal with Google and Shutterstock’s collaboration with OpenAI, using its extensive photo library.
But these arrangements have sparked considerable dissent within the creative community, particularly among artists and writers, who express concerns about their work being repurposed for AI training. This has led to a delicate balancing act for companies striving to satisfy their user base while exploring cutting-edge AI technologies, as evidenced by the mixed reactions within communities like DeviantArt.
Details surrounding any potential agreement between Automattic and the AI firms, including financial implications for Automattic, remain under wraps. Automattic, a veteran in web hosting with WordPress.com and WordPress VIP, has faced challenges in devising profitable strategies for Tumblr, which it acquired from Verizon in 2019. Last year, this led to an announcement about scaling back its ambitions for the site, reflecting the ongoing complexities of integrating social media platforms with emerging AI technologies.
READ MORE
- Safer Automation: How Sophic and Firmus Succeeded in Malaysia with MDEC’s Support
- Privilege granted, not gained: Intelligent authorization for enhanced infrastructure productivity
- Low-Code produces the Proof-of-Possibilities
- New Wearables Enable Staff to Work Faster and Safer
- Experts weigh in on Oracle’s departure from adland