
Alibaba Cloud has launched two open-source large vision language models. (Image – Shutterstock)
Alibaba Cloud launches two open-source large vision language models
- Alibaba Cloud unveils two open-source large vision language models.
- The models, Qwen-VL and Qwen-VL-Chat, can comprehend images, texts, and bounding boxes in prompts.
- The two models have had over 400,000 downloads within a month of their launch.
When it comes to technology, Alibaba Cloud has always made it clear that its technology is available for all. Given the pace of generative AI technology, the open-source community has also been working to develop new use cases and improve the capabilities of the technology.
While there are some concerns about how open-source code materials are being utilized by some generative AI tools, the general understanding is that everyone can still benefit from and contribute to the technology.


As such, Alibaba Cloud has launched two open-source large vision language models (LVLM). The models, Qwen-VL and Qwen-VL-Chat, can comprehend images, texts, and bounding boxes in prompts. The LVLM models can also facilitate multi-round question-answering in both English and Chinese.
What are large vision language models?
Similar to large language models (LLM), an LVLM is trained extensively on massive datasets containing images and corresponding textual descriptions. The model understands the relationship between visual content and natural language expressions. An extension of computer vision and natural language processing techniques, LVLMs facilitate tasks that involve processing and generating information in both visual and textual forms.
Hugging Face, an AI platform, breaks down LVLM into three key elements—an image encoder, a text encoder, and a strategy to fuse information from the two encoders. These essential components are intricately interconnected. LVLM continues to undergo significant changes. Prior approaches have utilized manually crafted image descriptors along with pre-trained word vectors or frequency-based TF-IDF features.
“LLMs have notably accelerated progress towards artificial general intelligence (AGI), with their impressive zero-shot capacity for user-tailored tasks, endowing them with immense potential across a range of applications. However, in the field of computer vision, despite the availability of numerous powerful vision foundation models (VFMs), they are still restricted to tasks in a pre-defined form, struggling to match the open-ended task capabilities of LLMs,” explain researchers on using LLM for vision-centric tasks.
In a research paper, researchers point out that an LLM-based framework for vision-centric tasks treats images as a foreign language and aligns vision-centric tasks with language tasks that can be flexibly defined and managed using language instructions.
The researchers also highlight that “an LLM-based decoder can then make appropriate predictions based on these instructions for open-ended tasks. Extensive experiments show that the proposed VisionLLM can achieve different levels of task customization through language instructions, from fine-grained object-level to coarse-grained task-level customization, all with good results.”

A Tweet on the new release by Alibaba Cloud.
Qwen-VL and Qwen-VL-Chat
Qwen-VL is the multimodal version of Qwen-7B, Alibaba Cloud’s 7-billion-parameter model of its large language model, Tongyi Qianwen. Qwen-VL is also available on ModelScope as open-source. It is capable of understanding both image inputs and text prompts in English and Chinese. Qwen-VL can perform various tasks such as responding to open-ended queries related to different images and generating image captions.
The features of Qwen-VL include:
- Strong performance – It significantly surpasses existing open-source LVLMs under similar scale settings on multiple English evaluation benchmarks, including Zero-shot caption, VQA, DocVQA, and Grounding.
- Multi-lingual LVLM supports text recognition – Qwen-VL naturally supports multi-lingual conversations and promotes end-to-end recognition of bilingual text in images in both Chinese and English.
- Multi-image interleaved conversations – This feature allows for the input and comparison of multiple images, as well as the ability to specify questions related to the images and engage in multi-image storytelling.
- First generalist model supports grounding in Chinese – Detecting bounding boxes through open-domain language expressions in both Chinese and English.
- Fine-grained recognition and understanding – Compared to the 224 resolution currently used by other open-source LVLMs, the 448 resolution promotes fine-grained text recognition, document QA, and bounding box annotation.
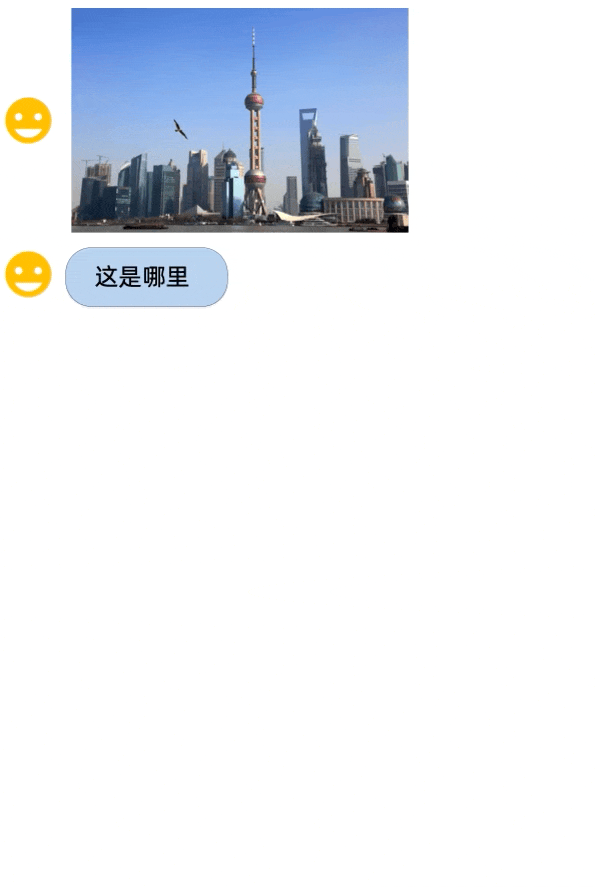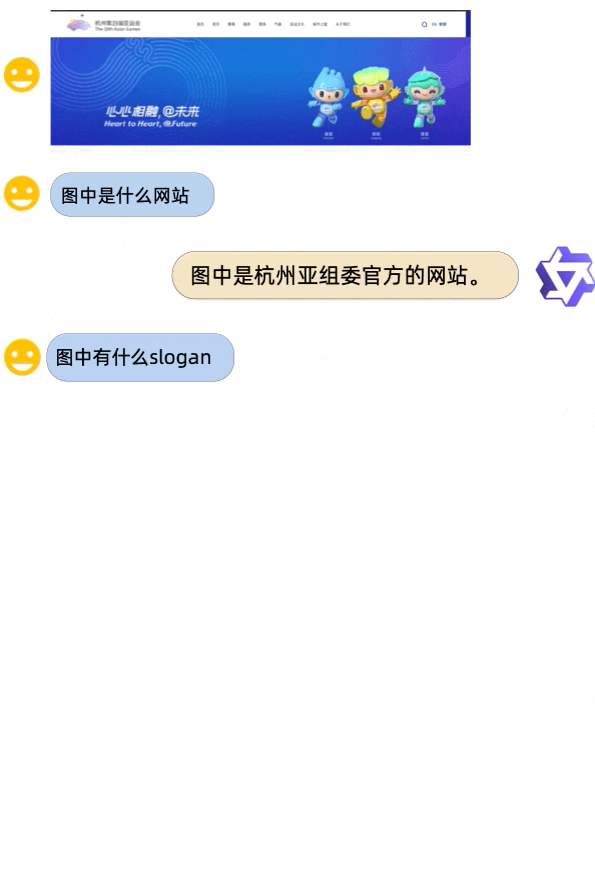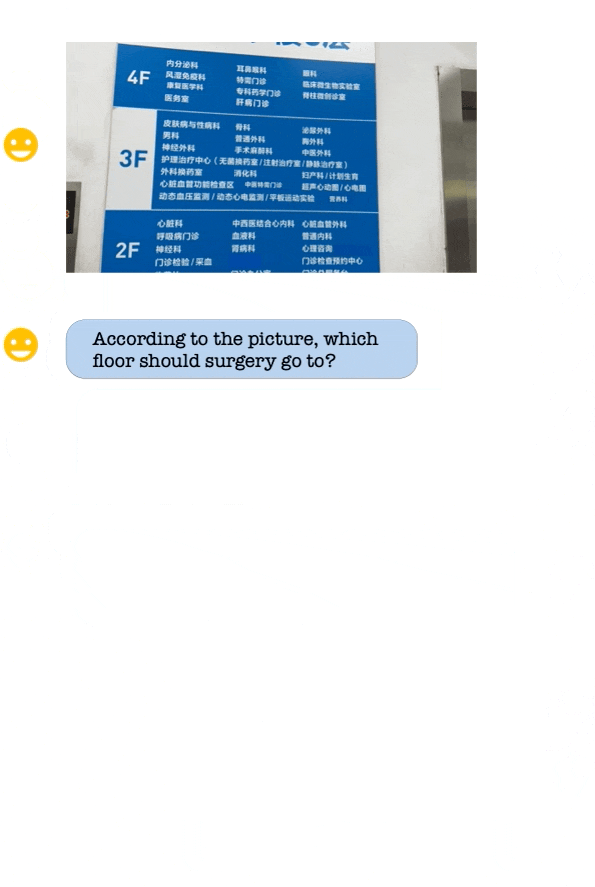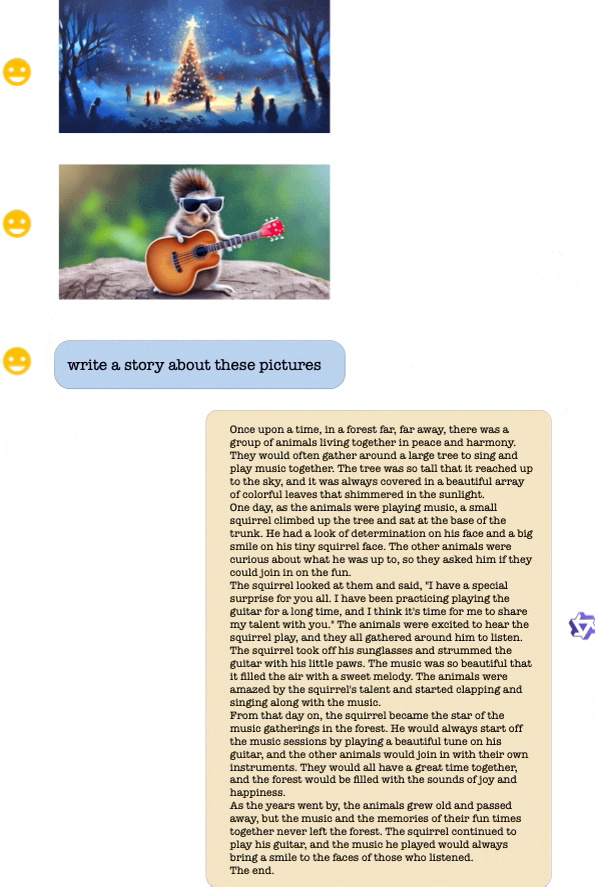
A demo of Qwen-VL. (Source – Alibaba Cloud)
Compared to other open-source large vision language models that can process and understand images in 224×224 resolution, Qwen-VL can handle image input at a resolution of 448×448, resulting in better image recognition and comprehension. Qwen-VL also recorded outstanding performance on several visual language tasks, including zero-shot captioning, general visual question-answering, text-oriented visual question-answering, and object detection.
Additionally, Qwen-VL-Chat caters to more complex interactions, such as comparing multiple image inputs and engaging in multi-round question-answering. The AI assistant leverages alignment techniques and exhibits a range of creative capabilities. This includes writing poetry and stories based on input images, summarizing the content of multiple pictures, and solving mathematical questions displayed in images.
In the benchmark test of Alibaba Cloud, Qwen-VL-Chat has also achieved leading results in both Chinese and English for text-image dialogue and alignment levels with humans. This test involved over 300 images, 800 questions, and 27 categories.

Multi-round question answering via the Qwen-VL-Chat model. (Source – Alibaba Cloud)
Alibaba Cloud and open source
In an interesting move by Alibaba Cloud, the tech company has shared the model’s code, weights, and documentation with academics, researchers, and commercial institutions worldwide. With democratizing AI technology on the agenda for most AI companies, the code is available to the open-source community via ModelScope and Hugging Face.
The introduction of these models, with their ability to extract meaning and information from images, holds the potential to revolutionize interactions with visual content. For instance, leveraging their image comprehension and question-answering capabilities, these models could provide informational assistance to visually impaired individuals during online shopping in the future.
Since these models have been open-sourced, the two models have garnered over 400,000 downloads within a month of their launch. For commercial uses, companies with over 100 million monthly active users can request a license from Alibaba Cloud.
The official repo of Qwen-VL (通义千问-VL) chat & pretrained large vision language model proposed by Alibaba Cloud.
READ MORE
- The threat of fraud networks in the APAC: KYC and beyond
- Next-gen CX is based on customer communication management systems.
- Enhancing Business Agility with SASE: Insights for CIOs in APAC
- 3 Steps to Successfully Automate Copilot for Microsoft 365 Implementation
- Trustworthy AI – the Promise of Enterprise-Friendly Generative Machine Learning with Dell and NVIDIA