
Google is sparking conversations on copyright respect and proper attribution in training generative AI’s LLMs. (Source – Shutterstock)
AI, web traffic, and data privacy: Meta tags beyond Robots.txt
|
Getting your Trinity Audio player ready... |
- Google advocates for new AI data control standards.
- ‘Usage-rights’ meta tags are proposed as a solution to web data control in the AI age.
During Google I/O, Google introduced new AI-focused products and shared its vision for responsible AI development, incorporating robust data privacy standards. Google emphasized its commitment to responsible AI development, aiming to maximize societal benefits while mitigating challenges, all under Google’s AI principles and a strong commitment to customer privacy.
As new technologies emerge, they present opportunities for the web community to establish standards and protocols supporting its continuous evolution. The robots.txt standard, established by the web community nearly three decades ago, is a notable example. It provides a simple and transparent means for web publishers to manage how search engines crawl their content.
According to Google, “we believe it’s time for the web and AI communities to explore additional machine-readable means for web publisher choice and control for emerging AI and research use cases.”


So, what exactly is Google suggesting? Google advocates for developing refined mechanisms that give web publishers more control, especially within AI applications and research. This signifies a future where AI, not just browses and indexes the web, but also interacts with it in more complex ways, guided by the decisions of the content creators.
Engaging the community is essential. Google invites members from the web and AI communities to contribute to the development of a new protocol. The company is initiating a public discussion, seeking various perspectives from web publishers, civil society, academia, and other sectors globally. Although the company plans to convene those interested in contributing in the upcoming months, no immediate changes are expected.
OpenAI’s decision to turn off the browse with Bing feature in ChatGPT after it was found accessing paywalled content without consent could be a contributing factor to why Google is considering alternatives to the robots.txt protocol.
The impact of large language models on web traffic and data privacy
Here’s where the issue of Large Language Models (LLMs) like ChatGPT comes into the picture. For some businesses, LLMs scraping their content may not pose significant problems. However, these models present a challenge for media and publishing companies whose core function is content creation.
Once LLMs scrape and learn from this proprietary content, they can repurpose it freely, potentially undermining the authority and traffic of the original source. This has a threefold impact on media companies:
- Loss of web traffic: AI tools like ChatGPT can decrease visits to the original content sources. Excessive requests from scraper bots can also slow down sites and increase infrastructure costs.
- Unauthorized usage of unique content: Public accessibility doesn’t equate to free use. Unapproved replication can erode a site’s market influence, credibility, and disrupt its media model.
- Declining trust in data privacy: Scrapers indiscriminately gather all accessible information for large language models, which can lead to privacy concerns.
So, how can you protect your business from these scrapers? Currently, you can utilize your robots.txt file to instruct major LLM scrapers like CCBot and ChatGPT-User to refrain from scraping your site. However, if many companies attempt to block LLMs from acquiring data for training, some LLMs may choose to disregard the robots.txt files. As fraudulent activities, bot developers, and bots continue to evolve, the risk landscape becomes increasingly unpredictable, underscoring the need for a specialized solution that is continuously monitored and updated for maximum effectiveness.
Scraping has recently been identified as a preliminary threat that can pave the way for more severe attacks. The most effective strategy to ensure your content remains protected in the future is to adopt an adaptable bot and fraud management solution capable of identifying and halting evolving bots, regardless of the approach they adopt.
Google noted our growing comfort with allowing bot access to websites using robots.txt and other structured data. But we may see new methods adopted in the future. These methods are still under discussion.
It’s important to note that not all LLMs use crawlers or identify themselves. Web crawlers, primarily employed by search engines to gather and index web data, aren’t used in the design of language learning models like OpenAI’s GPT-3 or GPT-4. These models are trained on various datasets, including books, websites, and other textual forms, to generate human-like text. Their main objective isn’t to index or search the web but to produce high-quality, contextually relevant responses.
Thus, protocols like robots.txt, which direct the actions of web crawlers, may not be as relevant to LLMs as they are to search engines. However, the overarching principles of respecting user privacy and choice remain crucial. This leads to discussions on how AI and LLMs should interact with online data and the standards guiding their usage.
Additionally, the maximum file size of a robots.txt file is capped at 500 kb, according to the newly suggested robots.txt standard. Therefore, a large publisher might face challenges with their robots.txt file if they need to block numerous LLM crawlers or specific URL patterns and other bots.
Beyond crawling: The indexation and manipulation of data
Current methods like the use of robots.txt only offer binary choices: allow or disallow crawling. For website owners, it’s a challenging decision as entirely blocking Googlebot or Bingbot to restrict their AI products’ data access could mean missing out on the extensive visibility provided by these search engines’ indexing.
To accommodate the evolving landscape of AI and machine learning, we may need to establish new protocols and standards that offer more sophisticated control. For instance, webmasters could be allowed to specify different levels of access for different uses. They might enable search indexing but disallow usage for AI training or other services.
Such a nuanced approach could help balance data protection and enable valuable services. Although implementing and managing granular permission settings could be more complex, as web data usage evolves, such an approach might be worth pursuing. However, it demands collaboration among web publishers, search engine providers, and other web community members to develop and agree on such standards.
While the robots.txt file primarily handles the crawling aspect, the current debate is more concerned with data utilization and is largely connected with the indexation or processing phase. The robots.txt file should be considered a backup option rather than the primary focus.
The robots.txt file’s functionality remains efficient for standard web crawlers, and there’s no pressing need to adapt it for LLM crawlers. The emphasis, however, should be on the indexation and manipulation of crawled data, not the act of crawling.
Instead of starting from scratch, the web already has established solutions for managing data usage concerning copyrights, such as the Creative Commons licensing system.
After a publisher identifies an appropriate license, it’s essential to have an effective communication method. Yet again, the robots.txt file may not be the best tool. Just because a page needs to be exempt from search engine crawling doesn’t mean it lacks value or shouldn’t be accessible for LLMs. These are distinct scenarios.
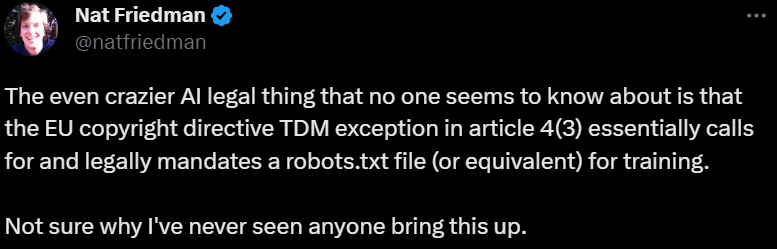
A Twitter user, @natfriedman, tweeted on how EU legally mandates a robots.txt file. (Source – Twitter)
A potential solution: Meta tags and the “usage-rights” protocol
Thus, meta tags could be a suitable option to differentiate these situations and offer a more sophisticated yet straightforward approach for publishers.
Meta tags embedded within a webpage’s HTML could provide the solution we seek. Unlike the blanket approach of the ‘robots.txt’ file, meta tags offer flexibility as they can be set page-by-page. They provide a simplified yet nuanced method for publishers to differentiate data usage rules for traditional search engine crawling and LLM use.
Meta tags can be added at a page level, within a theme, or the content, without needing additional access rights beyond the ability to edit the HTML of the published content. Importantly, while meta tags don’t halt crawling like ‘noindex’, they can dictate the usage rights of the published data.
Copyright tags, such as those from Dublin Core, can be used. However, these could potentially conflict with the broader objective of establishing more precise data usage control in the context of AI technologies. Thus, it’s proposed to introduce a new meta tag – “usage-rights” – that can provide clear instructions about data usage to AI technologies without causing conflicts.
The ‘usage-rights’ meta tag could also be supported in HTTP Headers, similar to how ‘noindex’ is supported in the X-Robots-Tag. This would help LLMs crawlers manage their resources more efficiently, as they only need to check the HTTP Headers to determine the usage rights.
However, the proposed meta tag solution isn’t perfect. Like the ‘robots.txt’ method, its effectiveness relies on recognition and adherence by the companies utilizing the data for their AI products. Neither approach can prevent the unauthorized use of content by ill-intentioned actors.
In conclusion, the suggested meta tag method provides a more nuanced and adaptable approach to data usage control than the existing methods. As we navigate the complexities of the AI era, evolving our standards and protocols is critical to support the web’s future development. This proposed solution is an essential step in that direction.
READ MORE
- Safer Automation: How Sophic and Firmus Succeeded in Malaysia with MDEC’s Support
- Privilege granted, not gained: Intelligent authorization for enhanced infrastructure productivity
- Low-Code produces the Proof-of-Possibilities
- New Wearables Enable Staff to Work Faster and Safer
- Experts weigh in on Oracle’s departure from adland